When designing a database, choosing an appropriate primary key is crucial for performance and maintainability. While UUIDv4 (Universally Unique Identifier version 4) is often considered for its uniqueness, it might not be the best choice for a primary key in many scenarios. This article will explain why UUIDv4 can be problematic, how a B+ tree index works, and why the lack of ordering in UUIDv4 can degrade performance.
Table of contents
Open Table of contents
What is UUIDv4?
UUIDv4 is a 128-bit identifier generated using random numbers. It has the following structure:
xxxxxxxx - xxxx - 4xxx - yxxx - xxxxxxxxxxxxHere, x is any hexadecimal digit and y is one of 8, 9, A, or B. UUIDv4 is designed to be globally unique, which makes it attractive for distributed systems where uniqueness across different nodes is required.
The problem with that type of ID, is that they have a random nature, you can’t order it in a way to organize them in most of the data structures that traditional databases commonly use.
How a B+ Tree Index Works
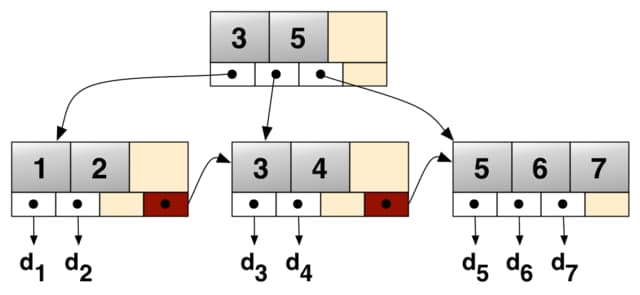
To understand why this kind of ID is not ideal for primary keys, it’s important to understand how a B+ tree index works. B+ trees are commonly used as index structures in databases(e.g., Postgresq, MySQL, SQLite, SQLServer) due to their balanced nature and efficient range queries.
Structure of a B+ Tree
A B+ tree consists of nodes organized in a hierarchical structure:
- Root Node: The top node in the tree.
- Internal Nodes: Nodes between the root and the leaf nodes, containing keys and pointers to child nodes.
- Leaf Nodes: The bottom level nodes, containing the actual data pointers (or row IDs).
- Each node in a B+ tree contains multiple keys in a sorted order. The tree maintains its balance by ensuring all leaf nodes are at the same depth.
Operations in a B+ Tree
- Insertion: When a new key is inserted, it’s placed in the correct position in the leaf node to maintain order. If the leaf node is full, it’s split, and the middle key is promoted to the parent node.
- Search: Searching for a key involves traversing the tree from the root to the leaf nodes, following the pointers based on key comparisons.
- Deletion: When a key is deleted, the tree rebalances itself to maintain its properties.
Why Random IDs are Bad for B+ Tree Indexes
Lack of Order
The primary issue with UUIDv4 is its randomness. B+ trees rely on the order of keys to maintain balance and efficiency. Since UUIDv4 values are random, they do not provide any inherent order. This lack of order has several negative implications:
- Insertions Are Inefficient: When new UUIDv4 values are inserted, they are likely to be placed in random positions within the leaf nodes. This randomness causes frequent splits and rebalancing of the tree, leading to increased overhead.
- Poor Cache Performance: Ordered data tends to be localized, meaning related data is stored close together. This locality improves cache performance. Randomly distributed UUIDv4 values scatter data, reducing cache efficiency.
- Fragmentation: Over time, the random insertion of UUIDv4 values can cause fragmentation in the index, leading to inefficient use of space and further degrading performance.
Increased Index Size
UUIDv4 values are 128-bit, which is significantly larger than typical integer-based keys (e.g., 32-bit or 64-bit). Larger keys increase the size of the B+ tree, requiring more memory and disk space to store the index. This increased size can also slow down search operations as more data needs to be read and processed.
Alternatives to UUIDv4 for Primary Keys
Given the drawbacks of UUIDv4, here are some alternative approaches for primary keys:
- Auto-Incrementing Integers: Using auto-incrementing integers (e.g., BIGINT) provides ordered, compact keys that work well with B+ tree indexes.
- UUIDv7: UUIDv7 includes a timestamp component, providing some level of order. While not as compact as integers, they can be a better option than UUIDv4 for distributed systems requiring unique keys.
- CUID: CUID (Collision-resistant Unique Identifier) is designed for horizontal scalability and high performance. CUIDs are shorter than UUIDs and incorporate time components, reducing fragmentation in B+ trees.
- ULID: ULID (Universally Unique Lexicographically Sortable Identifier) provides unique identifiers that are lexicographically sortable.
Conclusion
While UUIDv4 offers unique identifiers, its random nature makes it a poor choice for primary keys in databases, particularly those using B+ tree indexes. Keep this in mind to avoid choosing a unique ID generator with similar characteristics.
By understanding the implications of your primary key choice and how indexing structures like B+ trees work, you can make informed decisions that optimize your database’s performance and scalability.